在数据爆炸式增长的时代,企业对数据价值的挖掘日益迫切。传统的集中式、依赖专业IT团队的数据处理模式,因其流程冗长、响应迟缓,已难以满足业务部门敏捷、实时的分析需求。在此背景下,以自动化为核心的自服务大数据治理与数据处理服务应运而生,正重塑着企业数据运营与管理的方式。
一、核心理念:赋能业务,释放数据潜力
自服务大数据治理的本质,是借助先进的自动化平台与工具,将数据处理、质量管控、安全合规等复杂技术能力“封装”成简单易用的服务,直接交付给业务分析师、数据科学家及一线决策者。其核心目标在于降低数据使用的技术门槛,让业务用户能够自主、高效地发现、获取、准备和分析可信的数据,从而加速数据驱动决策的闭环。自动化是这一切得以实现的基石,它贯穿于数据发现、质量检查、血缘追踪、策略执行等各个环节,确保治理不成为效率的瓶颈,而是可靠性与敏捷性的保障。
二、自动化在数据处理服务中的关键作用
- 智能数据发现与编目:自动化爬虫和元数据采集工具能够持续扫描数据源,自动识别数据结构、内容、敏感信息,并构建可搜索的数据目录。结合AI分类与打标,用户能像使用搜索引擎一样快速找到所需数据资产。
- 自动化数据质量监控与修复:预设的数据质量规则(如完整性、一致性、准确性规则)可被自动化引擎持续执行。一旦发现异常,系统能自动触发告警,甚至根据预设逻辑尝试自动修复或隔离问题数据,确保流入下游的数据始终可信。
- 策略即代码与合规自动化:数据安全策略(如访问控制、脱敏、加密)和数据生命周期管理策略(如保留、归档、删除)可以代码化定义。自动化引擎确保这些策略在数据创建、流转、使用的全过程中被一致、无误地强制执行,极大降低了人工管理的风险和成本。
- 自助式数据准备与管道:用户通过直观的拖拽界面或自然语言描述数据转换需求,后台自动化引擎将其转化为可执行的数据处理流水线(ETL/ELT),自动进行数据清洗、整合、转换,并将结果数据集发布到指定位置供后续分析使用。
三、构建以自动化为基础的自服务数据处理平台
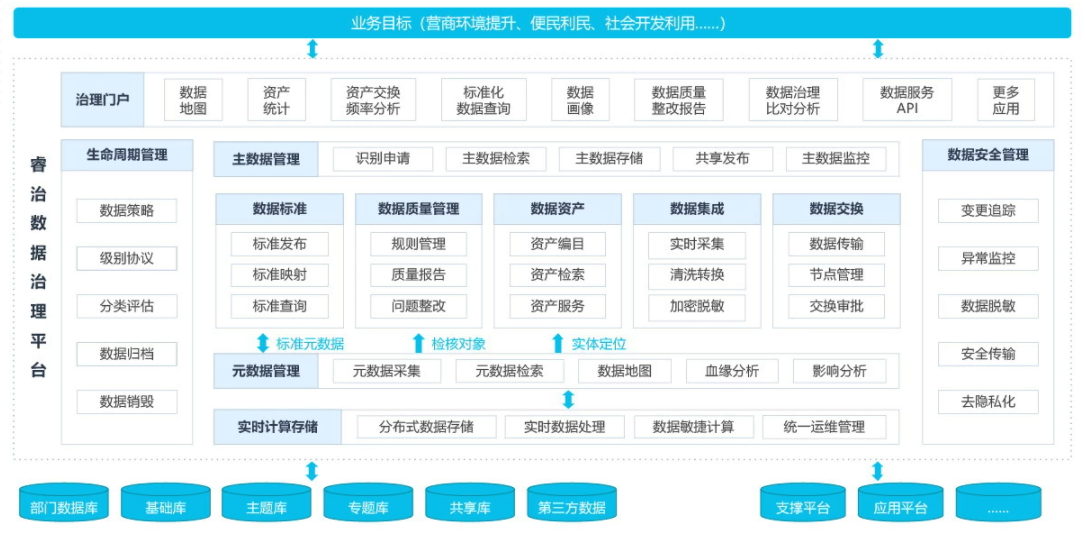
一个成功的自服务数据治理体系需要强大的平台支撑,该平台通常具备以下特征:
- 统一门户与交互体验:提供一站式访问入口,集成数据目录、质量报告、分析工具和工单系统。
- 可配置的自动化工作流引擎:允许管理员灵活编排数据治理任务流程,如从数据申请、审批、授权到交付的全程自动化。
- 嵌入式治理与主动推荐:将治理能力(如质量评分、血缘视图、使用条款)嵌入到用户日常使用的分析工具(如BI工具、Notebook)中,并根据用户行为智能推荐相关数据集或预警潜在问题。
- 全链路血缘与影响分析自动化:自动捕获和可视化数据从源到端的完整流动与转换关系。当上游数据或规则发生变更时,能自动分析并预警下游影响范围,实现主动治理。
四、挑战与未来展望
尽管优势明显,但实施过程也面临挑战:如何平衡业务自主性与必要的管控?如何确保自动化规则的准确性与适应性?如何建立与自服务模式配套的组织文化、角色与技能?
随着人工智能与机器学习技术的深度融合,自服务大数据治理的自动化水平将迈向新高度。AI不仅将用于优化数据处理任务本身,还将更深入地参与治理策略的智能推荐、异常模式的主动发现、乃至自主决策与优化,最终实现真正“智能自治”的数据环境。
以自动化为核心的自服务大数据治理,并非要取代专业的数仓团队或数据工程师,而是通过技术手段将他们的专业知识产品化、服务化、平民化。它构建了一个安全、可控且高效的“数据市场”,让数据消费者能随时随地获取高质量“数据产品”,从而真正释放数据作为核心生产要素的全部潜能,驱动企业创新与增长。这标志着数据处理服务正从成本中心式的“后台支撑”,向赋能型、价值创造的“战略引擎”加速转型。